分布式數據庫是偽需求
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
隨著硬件技術的進步,單機數據庫的容量和性能已達到了前所未有的高度。而分布式(TP)數據庫在這種變革面前極為無力,和“數據中臺”一樣穿著皇帝的新衣,處于自欺欺人的狀態(tài)里。太長不看分布式數據庫的核心權衡是:“以質換量”,犧牲功能、性能、復雜度、可靠性,換取更大的數據容量與請求吞吐量。但分久必合,硬件變革讓集中式數據庫的容量與吞吐達到一個全新高度,使分布式(TP)數據庫失去了存在意義。 以 NVMe SSD 為代表的硬件遵循摩爾定律以指數速度演進,十年間性能翻了幾十倍,價格降了幾十倍,性價比提高了三個數量級。單卡 115 TB+, 4K隨機讀寫 IOPS 可達 3M IOPS,延時 50μs/9μs,價格不到 200 ¥/TB·年。跑 PostgreSQL 單機能有一兩百萬的點寫/點查 QPS。 真正需要分布式數據庫的場景屈指可數,典型的中型互聯(lián)網公司/銀行請求數量級在幾萬到幾十萬QPS,不重復TP數據在百TB上下量級。真實世界中 99.99 % 以上的場景用不上分布式數據庫,剩下1%也大概率可以通過經典的水平/垂直拆分等工程手段解決。 頭部互聯(lián)網公司可能有極少數真正的適用場景,然而此類公司沒有任何付費意愿。市場根本無法養(yǎng)活如此之多的分布式數據庫內核,能夠成活的產品靠的也不見得是分布式這個賣點。HATP 、分布式單機一體化是迷茫分布式TP數據庫廠商尋求轉型的掙扎,但離 PMF 仍有不小距離。 互聯(lián)網的牽引“分布式數據庫” 并不是一個嚴格定義的術語。狹義上它與 NewSQL:cockroachdb / yugabytesdb / tidb / oceanbase / TDSQL 等數據庫高度重合;廣義上 Oracle / PostgreSQL / MySQL / SQL Server / PolarDB / Aurora 這種跨多個物理節(jié)點,使用主從復制或者共享存儲的經典數據庫也能歸入其中。在本文語境中,分布式數據庫指前者,且只涉及核心定位為事務處理型(OLTP)的分布式關系型數據庫。 分布式數據庫的興起源于互聯(lián)網應用的快速發(fā)展和數據量的爆炸式增長。在那個時代,傳統(tǒng)的關系型數據庫在面對海量數據和高并發(fā)訪問時,往往會出現性能瓶頸和可伸縮性問題。即使用 Oracle 與 Exadata,在面對海量 CRUD 時也有些無力,更別提每年以百千萬計的高昂軟硬件費用。 互聯(lián)網公司走上了另一條路,用諸如 MySQL 這樣免費的開源數據庫自建。老研發(fā)/DBA可能還會記得那條 MySQL 經驗規(guī)約:單表記錄不要超過 2100萬,否則性能會迅速劣化;與之對應的是,數據庫分庫分表開始成為大廠顯學。 這里的基本想法是“三個臭皮匠,頂個諸葛亮”,用一堆便宜的 x86 服務器 + 大量分庫分表開源數據庫實例弄出一個海量 CRUD 簡單數據存儲。故而,分布式數據庫往往誕生于互聯(lián)網公司的場景,并沿著手工分庫分表 → 分庫分表中間件 → 分布式數據庫這條路徑發(fā)展進步。 作為一個行業(yè)解決方案,分布式數據庫成功滿足了互聯(lián)網公司的場景需求。但是如果想把它抽象沉淀成一個產品對外輸出,還需要想清楚幾個問題: 十年前的利弊權衡,在今天是否依然成立? 互聯(lián)網公司的場景,對其他行業(yè)是否適用? 分布式事務數據庫,會不會是一個偽需求? 分布式的權衡“分布式” 同 “HTAP”、 “存算分離”、“Serverless”、“湖倉一體” 這樣的Buzzword一樣,對企業(yè)用戶來說沒有意義。務實的甲方關注的是實打實的屬性與能力:功能性能、安全可靠、投入產出、成本效益。真正重要的是利弊權衡:分布式數據庫相比經典集中式數據庫,犧牲了什么換取了什么? 
分布式數據庫的核心Trade Off 可以概括為:“以質換量”:犧牲功能、性能、復雜度、可靠性,換取更大的數據容量與請求吞吐量。 NewSQL 通常主打“分布式”的概念,通過“分布式”解決水平伸縮性問題。在架構上通常擁有多個對等數據節(jié)點以及協(xié)調者,使用分布式共識協(xié)議 Paxos/Raft 進行復制,可以通過添加數據節(jié)點的方式進行水平伸縮。 首先,分布式數據庫因其內在局限性,會犧牲許多功能,只能提供較為簡單有限的 CRUD 查詢支持。其次,分布式數據庫因為需要通過多次網絡 RPC 完成請求,所以性能相比集中式數據庫通常有70%以上的折損。再者,分布式數據庫通常由DN/CN以及TSO等多個組件構成,運維管理復雜,引入大量非本質復雜度。最后,分布式數據庫在高可用容災方面相較于經典集中式主從并沒有質變,反而因為復數組件引入大量額外失效點。  SYSBENCH吞吐對比[2] 在以前,分布式數據庫的利弊權衡是成立的:互聯(lián)網需要更大的數據存儲容量與更高的訪問吞吐量:這個問題是必須解決的,而這些缺點是可以克服的。但今日,硬件的發(fā)展廢問了 量 的問題,那么分布式數據庫的存在意義就連同著它想解決的問題本身被一并抹除了。
 新硬件的沖擊摩爾定律指出,每18~24個月,處理器性能翻倍,成本減半。這個規(guī)律也基本適用于存儲。從2013年開始到2023年是5~6個周期,性能和成本和10年前比應該有幾十倍的差距,是不是這樣呢? 讓我們看一下 2013 年典型 SSD 的性能指標,并與 2023 當下主流 PCI-e Gen4 NVMe SSD 的典型產品進行對比。不難發(fā)現:硬盤4K隨機讀寫 IOPS從 60K/40K 到了 1600K/600K,價格從 2220$/TB 到 40$/TB 。性能翻了 15 ~ 26 倍,價格便宜了 56 倍。
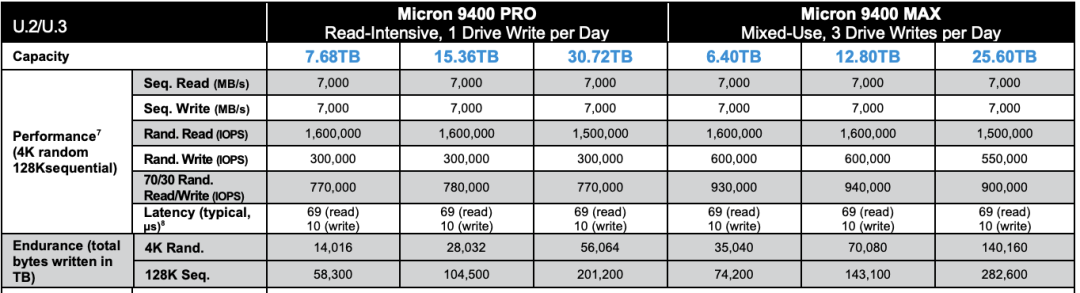 十年前,機械硬盤還是絕對主流。1TB 的硬盤價格大概七八百元,64GB 的SSD 還要再貴點。十年后,主流 3.2TB 的企業(yè)級 NVMe SSD 也不過三千塊錢。按五年質保折算,1TB每月成本只要 16塊錢,每年成本不到 200塊。作為參考,云廠商號稱物美價廉的 S3對象存儲都要 1800¥/TB·年。 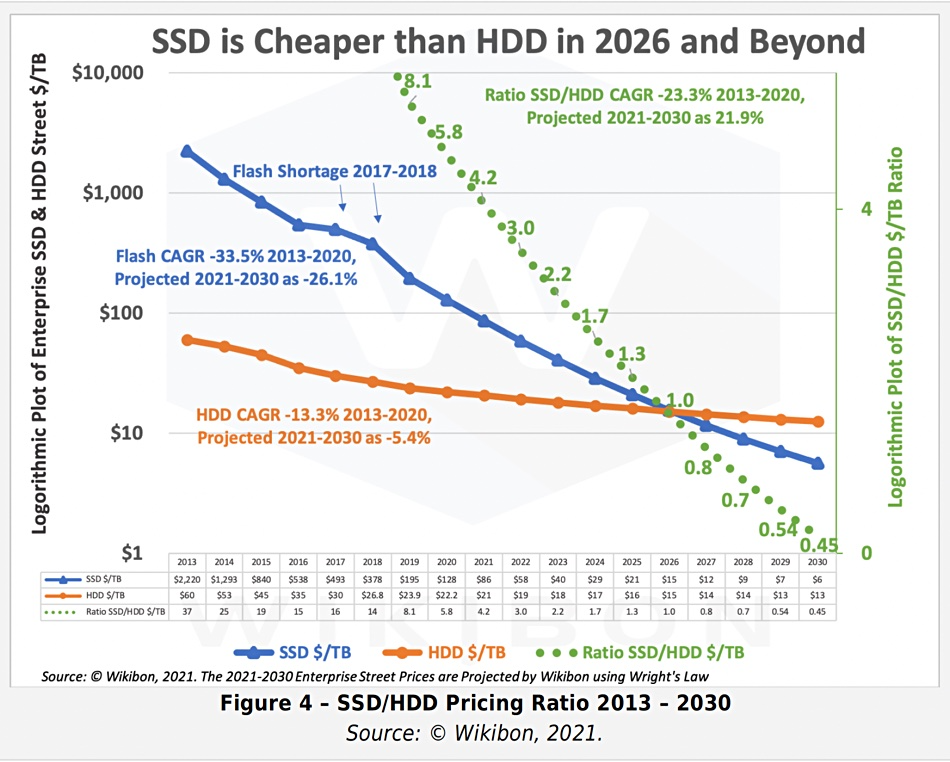 典型的第五代本地 NVMe 磁盤單卡最大容量可達 32TB~ 64TB,提供 70μs/10μs 4K隨機讀/寫延遲,2500K/600K 的讀寫IOPS,第五代更是有著單卡十幾GB/s 的驚人帶寬。 這樣的卡配上一臺經典 Dell 64C / 512G 服務器,IDC代維5年折舊,總共十萬塊不到。而這樣一臺服務器跑 PostgreSQL 或者 MySQL ,sysbench 單機點寫入可以接近百萬QPS,點查詢干到兩百萬 QPS 不成問題。
這是什么概念呢?對于一個典型的中型互聯(lián)網公司/銀行,數據庫請求數量級通常在幾萬/幾十萬 QPS這個范圍;不重復的TP數據量級在百TB上下浮動。考慮到使用硬件存儲壓縮卡還能有個幾倍壓縮比,這類場景在現代硬件條件下,有可能集中式數據庫單機單卡就直接搞定了[6]。Cursor從分布式 Yugabyte換到單機PG RDS,就是一個非常有代表性的例子。 在以前,用戶可能需要先砸個幾百萬搞 exadata 高端存儲,再花天價購買 Oracle 商業(yè)數據庫授權與原廠服務。而現在做到這些,硬件上只需一塊幾千塊的企業(yè)級 SSD 卡即可起步;像 PostgreSQL 這樣的開源 Oracle 替代,最大單表32TB照樣跑得飛快,不再有當年MySQL非要分表不可的桎梏。原本高性能的數據庫服務從情報/銀行領域的奢侈品,變成各行各業(yè)都能輕松負擔得起的平價服務[7]。 性價比是第一產品力,高性能大容量的存儲在十年間性價比提高了三個數量級,分布式數據庫曾經的價值亮點,在這種大力出奇跡的硬件變革下顯得軟弱無力。 偽需求的困境在當下,犧牲功能性能復雜度換取伸縮性有極大概率是偽需求。 在現代硬件的加持下,真實世界中 99%+ 的場景超不出單機集中式數據庫的支持范圍,剩下1%也大概率可以通過經典的水平/垂直拆分等工程手段解決。這一點對于互聯(lián)網公司也能成立:即使是全球頭部大廠,不可拆分的TP單表超過幾十TB的場景依然罕見。 NewSQL的祖師爺 Google Spanner 是為了解決海量數據伸縮性的問題,但又有多少企業(yè)能有Google的業(yè)務數據量?從數據量上來講,絕大多數企業(yè)終其生命周期的TP數據量,都超不過集中式數據庫的單機瓶頸,而且這個瓶頸仍然在以摩爾定律的速度指數增長中。從請求吞吐量上來講,很多企業(yè)的數據庫性能余量足夠讓他們把業(yè)務邏輯全部用存儲過程實現并絲滑地跑在數據庫中。 “過早優(yōu)化是萬惡之源”,為了不需要的規(guī)模去設計是白費功夫。如果量不再成為問題,那么為了不需要的量去犧牲其他屬性就成了一件毫無意義的事情。  在數據庫的許多細分領域中,分布式并不是偽需求:如果你需要一個高度可靠容災的簡單低頻 KV 存儲元數據,那么分布式的 etcd 就是合適的選擇;如果你需要一張全球地理分布的表可以在各地任意讀寫,并愿意承受巨大的性能衰減作為代價,那么分布式的 YugabyteDB 也許是一個不錯的選擇。如果你需要進行信息公示并防止篡改與抵賴,區(qū)塊鏈在本質上也是一種 Leaderless 的分布式賬本數據庫; 對于大規(guī)模數據分析OLAP來說,分布式可以說是必不可少(不過這種一般稱為數據倉庫,MPP);但是在事務處理OLTP領域,分布式可以說是大可不必:OTLP數據庫屬于工作性記憶,而工作記憶的特點就是小、快、功能豐富。即使是非常龐大的業(yè)務系統(tǒng),同一時刻活躍的工作集也不會特別大。OLTP 系統(tǒng)設計的一個基本經驗法則就是:如果你的問題規(guī)模可以在單機內解決,就不要去折騰分布式數據庫。
OLTP 數據庫已經有幾十年的歷史,現有內核已經發(fā)展到了相當成熟的地步。TP 領域標準正在逐漸收斂至 PostgreSQL,MySQL,Oracle 三種 Wire Protocol 。如果只是折騰數據庫自動分庫分表再加個全局事務這種“分布式”,那一定是沒有出路的。如果真能有“分布式”數據庫殺出一條血路,那大概率也不是因為“分布式”這個“偽需求”,而應當歸功于新功能、開源生態(tài)、兼容性、易用性、國產信創(chuàng)、自主可控這些因素。 迷茫下的掙扎分布式數據庫最大的挑戰(zhàn)來自于市場結構:最有可能會使用分布式TP數據庫的互聯(lián)網公司,反而是最不可能為此付費的一個群體。互聯(lián)網公司可以作為很好的高質量用戶甚至貢獻者,提供案例、反饋與PR,但唯獨在為軟件掏錢買單這件事上與其模因本能相抵觸。即使頭部分布式數據庫廠商,也面臨著叫好不叫座的難題。 近日與某分布式數據庫廠工程師閑聊時獲悉,在客戶那兒做 POC 時,Oracle 10秒跑完的查詢,他們的分布式數據庫用上各種資源和 Dirty Hack 都有一個數量級上的差距。即使是從10年前 PostgreSQL 9.2 分叉出來的 openGauss,都能在一些場景下干翻不少分布式數據庫,更別提 12 年后的 PostgreSQL 17 與 Oracle 23c 了。這種差距甚至會讓原廠都感到迷茫,分布式數據庫的出路在哪里?
所以一些分布式數據庫開始自救轉型, HTAP 是一個典型例子:分布式搞事務雞肋,但是做分析很好呀。那么為什么不能捏在一起湊一湊?一套系統(tǒng),同時可以做事務處理與分析喲!但真實世界的工程師都明白:AP系統(tǒng)和TP系統(tǒng)各有各的模式,強行把兩個需求南轅北轍的系統(tǒng)硬捏合在一塊,只會讓兩件事都難以成功。 不論是使用經典 ETL/CDC 推拉到專用 ClickHouse/Greenplum/Doris 去處理,還是邏輯復制到In-Mem列存的專用從庫,哪一種都要比用一個奇美拉雜交HTAP數據庫要更靠譜。甚至現在連分析都不一定非要分布式不可:一個最典的例子莫過于: TiDB 官網的 92C 478G 服務器跑 TPC-H 50 倉結果,跟DuckDB 單機用一臺 Mac 8C 64G 跑 300 倉結果的耗時基本相同。? 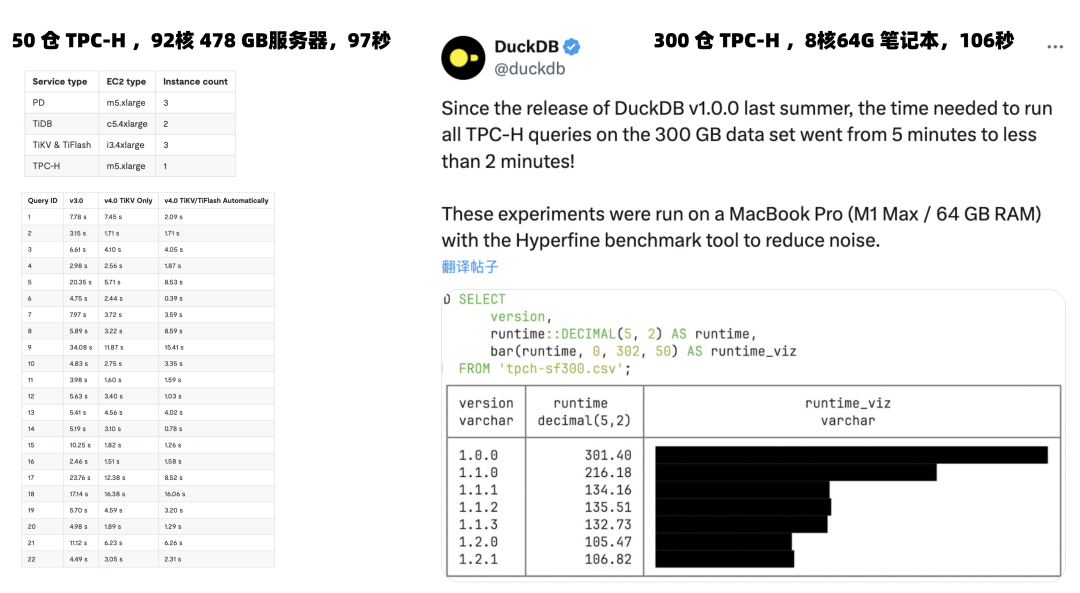 另一種思路是單機分布式一體化:打不過就加入:添加一個單機模式以規(guī)避代價高昂的網絡RPC開銷,起碼在那些用不上分布式的99%場景中,不至于在硬指標上被集中式數據庫碾壓得一塌糊涂 —— 用不上分布式沒關系,先拽上車別被其他人截胡! 目前 Oceanbase 是這樣做的。但這里的問題本質與 HTAP 是一樣的:強行整合異質數據系統(tǒng)沒有意義,如果這樣做有價值,那么為什么沒人去把所有異構數據庫整合一個什么都能做的巨無霸二進制 —— 數據庫全能王?因為這樣違背了KISS原則:Keep It Simple, Stupid!  分布式數據庫和數據中臺的處境類似[8]:起源于互聯(lián)網大廠內部的場景,也解決過領域特定的問題。曾幾何時乘著互聯(lián)網行業(yè)的東風,數據庫言必談分布式,火熱風光好不得意。卻因為過度的包裝吹捧,承諾了太多不切實際的東西,又無法達到用戶預期 —— 最終一地雞毛,成為皇帝的新衣。 TP數據庫領域還有很多地方值得投入精力:Leveraging new hardwares,積極擁抱 CXL,RDMA,NVMe 等底層體系結構變革;或者提供簡單易用的聲明式接口,讓數據庫的使用與管理更加便利;提供更為智能的自動駕駛監(jiān)控管控,盡可能消除運維性的雜活兒;使用擴展加強現有數據庫內核的能力,或者開發(fā)類似 Babelfish 的 MySQL / Oracle 兼容插件,實現關系數據庫 WireProtocol 統(tǒng)一。哪怕砸錢堆人提供更好的支持服務,都比一個 “分布式” 的偽需求噱頭要更有意義。 因時而動,君子不器。愿分布式數據庫廠商們找到自己的 PMF,做一些用戶真正需要的東西。 References
閱讀原文:https://mp.weixin.qq.com/s/FNhTCZk-SBVQkYhQ3zi_-g 該文章在 2025/4/22 18:17:23 編輯過 |
關鍵字查詢
相關文章
正在查詢... 的專業(yè)生產管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調度、堆場、車隊、財務費用、相關報表等業(yè)務管理,結合碼頭的業(yè)務特點,圍繞調度、堆場作業(yè)而開發(fā)的。集技術的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質期管理,貨位管理,庫位管理,生產管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886



 ?
?